Очередь сообщений. Анализ потоковых данных
Якимов Николай Михайлович
Очередь сообщений
Как собранные данные передаются в систему анализа и дальше по цепочке?
Вспоминая общую схему потоковой системы, речь будет идти о компоненте очереди сообщений.

Необходимость очереди сообщений
Зачем очередь сообщений?
Кажется, данные можно сразу передавать на анализ.
Ответ – распределённые системы. Проще – отсутствие сильных связей между компонентами.
Чтобы разорвать сильную связь, вводятся “прослойки”.
Очередь сообщений позволяет работать на более высоком уровне абстракции.
Основные концепции
Что именно понимается под очередями сообщений?
Здесь понимается в широком смысле.
Программные продукты:
- RabbitMQ
- ActiveMQ
- HornetQ
- NSQ
- ZeroMQ
- Apacke Kafka
- и др.
Компоненты очереди сообщений

Три главных компонента:
- Производитель сообщений
- Брокер сообщений
- Потребитель сообщений
Очереди абстрагируются брокером.

На этой схеме более очевидно, что происходит:
- Производитель отправляет сообщение брокеру
- Брокер получает сообщение и помещает его в очередь
- Потребитель запрашивает сообщение у брокера
- Брокер достаёт сообщение из очереди и передаёт потребителю
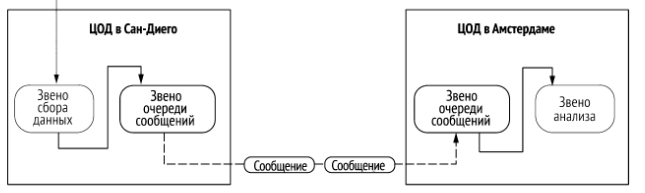
Изоляция производителей и потребителей
Одна из целей – ослабить связи.
Очередь сообщений ослабляет связь сбора данных и анализа.
Какие преимущества это даёт?
Если сообщения порождаются быстрее, чем получается обработать, как предотвратить “захлёбывание”?
“Противодавление” – мера того, насколько быстрее сообщения порождаются, чем обрабатываются. Аналогия с гидравликой.
Временный рост противодавления – нормально.
В системах “почти” реального времени, рост противодавления – признак проблемы.
Варианты:
Решение на стороне потребителей. При росте противодавления, можно увеличить число потребителей или сделать их быстрее.
Не всегда оправдано.
Управление производителем. Уменьшать плотность потока при росте противодавления.
Не все системы поддерживают. Тогда управление – на совести разработчика.
Поддержка – в основном в продуктах, с долговечными сообщениями.
Долговечные сообщения
Интересны не только в связи с противодавлением.
Могут обеспечивать устойчивость к сбоям связности сети.
Долговечные сообщения: не только устойчивость к сбоям, но и поддержка периодически активных потребителей.
Может быть интересно, если хочется обрабатывать одни и те же данные по-разному.
Пример: система дорожной навигации (типа Яндекс.Навигатор).
Семантика доставки сообщений
Три вида гарантий:
- Не более одного раза
- Не менее одного раза
- Ровно один раз
Какое лучше? Интуитивно – “ровно один раз”. Но цена – выше сложность, ниже производительность.
Точки отказа “только один раз”:
- Производитель
- Сеть между производителем и брокером
- Брокер
- Очередь сообщений
- Сеть между потребителем и брокером
- Потребитель
Не все системы дают гарантию “только один раз”.
Не фатально – можно реализовать вручную через координацию производителей и потребителей:
- Со стороны производителя. Не пытаться отправить сообщения повторно.
- Со стороны потребителя. Сохранять метаданные последнего сообщения.
Полезно хранить метаданные полезной нагрузки сообщения. Почти “бесплатно” возможность аудита данных.
Безопасность
Следует следить за:
- безопасностью данных при передачи и хранении
- разрешено ли производителям порождать сообщения (которые они порождают)
- разрешено ли потребителям потреблять данные (которые они потребляют)
Стоит обратить внимание:
- На этапе сбора данных:
- Можно ли аутентифицировать производителя?
- Авторизовать?
- При передаче сообщений:
- Как обеспечить безопасность передачи?
- При хранении сообщений:
- Как обеспечить безопасность хранения?
- На этапе очереди сообщений:
- Взаимная аутентификация брокеров?
- На этапе анализа данных:
- Можно ли аутентифицировать потребителя?
- Авторизовать?
Отказоустойчивость
Что произойдёт с данными, когда случится что-то нехорошее.
Если один из брокеров выйдет из строя? Если используется долговременное хранилище, риску подвержены только не записанные туда сообщения.
Способов снижения рисков:
- Ожидание производителем подтверждения записи сообщений на диск
- Реплицкация сообщения нескольким брокерам
- Минимизация хранимых в оперативной памяти данных
В случае разрыва сетевых соединений? При поддержке репликации, данные в относительной безопасности.
При выборе продукта, следует найти ответы:
- При отказе сети, выбирается ли в качестве реплики другой брокер?
- Что происходит при восстановлении сети?
- Есть ли возможность настроить временную задержку (“таймаут”), при которой считается, что сеть отказала?
- Что произойдёт с данными, если сеть не восстановится?
- Что произойдёт с данными, если брокер отключится от кластера в момент передачи ему сообщения от производителя?
При отказе хранилища? Следует найти ответы на вопросы:
- Существуют ли реплики потерянных в результате отказа СХД данных?
- Если реплицируемые данные не успели записать на диск до момента отказа: будут ли эти данные потеряны?
- Как восстановить брокера после отказа СХД?
Примеры
Финансы: обнаружение мошенничества
Вопросы:
- Как повлияет на бизнес длительное отсутствие связи между звеньями сбора данных и анализа?
- Данные за сколько дней можно потерять без последствий?
- Должны ли храниться старые данные?
- Какая семантика доставки сообщений нужна в этом случае?
- Отсутствие связи. Повлияет катастрофически.
- Потеря данных. Всегда с последствиями.
- Старые данные. Скорее всего, должны храниться.
- Семантика доставки. Скорее всего, “ровно один раз”.
Интернет вещей: “социальные” автоматы для продажи лимонада
Электронная коммерция: рекомендация товаров
Анализ потоковых данных

- анализ данных в движении
- архитектура потоковой обработки
- основные функции фреймворков
Анализ данных в движении
Концепция данных в движении (in-flight data) и непрерывных запросов.
Данные в движении – все кортежи в системе, от источника до клиента на выходе. Находящиеся в процессе обработки, или только что обработанные.
Данные “в покое” – записанные в постоянное хранилище.
Цель – быстрее получить данные из очереди сообщений. В идеале, анализ данных с тем же темпом, что и сбор данных.
В “традиционной” системе – меняющиеся запросы к статичным данным.
В потоковой системе – фиксированный запрос, динамические данные. Модель непрерывного запроса.
Пример: управление новостным агентством.
Традиционная система:
- Собрать данные с сайта
- Загрузить данные в СУБД
- Выполнить запрос к СУБД
- Предпринять действия
- Повторять каждые x минут/часов/дней
Потоковая система:
- Собрать поток данных
- Запустить запрос на активном потоке данных
- Предпринять соответствующие действия
Традиционная система проигрывает потоковой в отзывчивости.
Ещё раз ключевые различия:
- В традиционной системе, активная сторона – пользователь, система – пассивная. Набор данных статический.
- В потоковой системе, условно-пассивной стороной является запрос и клиент, создавший этот запрос, а активной – система.
В потоковой системе – инверсия потока упралвения.
Различие в обработке сбоев:
- Когда традиционная система не работает, данные не изменяются.
- Когда компонент анализа в потоковой системе не работает, приложения продолжают генерировать данные. После сбоя может понадобиться наверстать упущенное.
Различие в обработке сбоев:
- Если традиционная система отказывает в момент выполнения запроса, то повторное выполнение запроса – на совести приложения (или пользователя)
- Если потоковая система отказывает, после восстановления непрерывные запросы могут быть продолжены с прерванного места (хотя это не всегда необходимо). Часто с точки зрения клиента, всё выглядит так, как будто никакого сбоя вообще не было.
Приведём несколько примеров успеха:
- Маркетинг на основе поведения. McDonald’s, VMob (Plexure), увеличение конверсии увеличилась на 700%.
- Повышение эффективности дорожного движения. Veovo. Распределение нагрузки на дорожную сеть.
- Обнаружение мошенничества. По отчёту FICO, после внедрения в США анализа данных в реальном времени, потери от мошенничества с кредитными картами снизились на 70%
Архитектуры распределённой обработки
Общие подходы к распределённым системам.
На рынке немало технологий.
Из популярных OpenSource:
- Spark Streaming
- Storm
- Flink
- Samza
Проекты фонда Apache.
Общая архитектура

Пример с газовой турбиной:

Spark Streaming
Система Spark Streaming – поверх Apache Spark. Кроме Streaming:
- MLib
- SparkR
- GraphX
Архитектура Streaming:

Apache Storm
Storm – система потоковой обработки по принципу “один кортеж за раз”. Спроектирована для работы в режиме реального времени.
Архитектура Storm:

Концепции:
- Топология
- Spout (струя)
- Bolt (разряд)
Apache Flink
Flink – потокоориентированная система. Всё рассматривается как поток.
Программа для Flink состоит из:
- потоков
- преобразований
Выход – “сток”
Приложение для Flink – само по себе поток.
Облегчает композицию приложений.
Архитектура:

Apache Samza
Потоковая модель Samza несколько отличается. Использует поэтапную модель обработки потока. На базе Apache YARN и Apache Kafka.

Ключевые функции систем потоковой обработки
Семантика доставки сообщений
Похожа на семантику доставки в очередях. Определения те же, но выводы немного другие.
Семантики:
- Не более одного раза
- Не менее одного раза
- Ровно один раз
“Не более одного раза”, ошибки:
- потеря (отбрасывание) сообщения
- отказ обработчика
Семантика “не более одного раза” – самая простая
“Не менее одного раза” более сложная, поскольку потоковая система должна отслеживать каждое сообщение и подтверждение получения.
Потоковая задача может получить одно и то же сообщение несколько раз, задача должна быть идемпотентной.
Семантика “ровно один раз” ещё увеличивает сложность системы. Система должна ещё и обнаруживать дубликаты. Упрощает работу задачи.
Вообще, лучше всё равно делать задачи идемпотентными.
Какие именно гарантии нужны в каждом конкретном случае зависит, понятно, от характера решаемой задачи.
Управление состоянием
Если потоковый алгоритм более сложный, чем чистая обработка текущего сообщения (без зависимостей между сообщениями или от внешних данных), необходимость хранения состояния. Тогда – служба управления состоянием.

Отказоустойчивость
Вопрос не в том, сломается что-то или нет, а в том, когда это произойдёт. Поэтому – отказоустойчивость.
В компоненте анализа данных семь точек отказа:
- Входной поток данных.
- Сеть передачи входного потока.
- Потоковый обработчик.
- Связь с местом назначения.
- Место назначения.
- Потоковый диспетчер.
- Драйвер приложения.
Отказы со стороны входящего потока и места назначения (и связи с ними) должны корректно обрабатываться и связь должна автоматически восстанавливаться при первой возможности
Оставшиеся элементы:
- Потеря данных. Сюда относится потеря данных при передаче, и авария обработчика (теряются данные в памяти)
- Утрата контроля. Авария потокового диспетчера и/или драйвера.
Два подхода к репликации и координации:
- Резервирование
- Восстановление откатом