Системы хранения и доступа.
Якимов Николай Михайлович
Хранение данных
Поговорим о сохранении данных после обработки.

Варианты действий по завершению анализа:
- Отбросить данные (по результатам анализа)
- Передать данные потоковой платформе
- Сохранить данные для использования в режиме реального времени
- Сохранить данные для последующей пакетной обработки
Долговременное хранилище
Долговременное хранилище – если необходимо хранение исторических данных для последующей обработки в пакетном режиме.
Примеры: HDFS, HBase, реляционные СУБД и т.п.
Три принципиальных подхода:
- Сохранять каждое сообщение отдельно
- Сохранять сообщения пакетами, формируемыми в звене анализа
- Сохранять сообщения пакетами, формируемыми очередью сообщений
1 и 2 – прямая запись.
Потенциальные проблемы и риски:
- хранилище не справляется со скоростью потока ⇒ не сможем сохранить данные, возможно затормозим анализ
- при крахе компонента анализа велик шанс потерять данные
3 – непрямая запись.
Здесь связь между хранилищем и обработкой разрывается очередью.
Подходы, с очередью, рассмотренные ранее.
Данные из очереди извлекаются пакетным загрузчиком:
- Gobblin (sic!) компании LiknedIn
- Secor (https://github.com/pinterest/secor) компании Pinterest
Сохранение из Kafka в HDFS, Openstack Swift или другое.
Хранение данных в памяти
Цель потоковой системы – обработка данных в “почти” реальном времени. Для анализа может быть необходим какой-то объём исторических данных. Доступ должен быть максимально быстрым.
Максимально быстрый доступ – к данным в оперативной памяти.
Системы хранения – в 1000 или более раз медленнее оперативной памяти. Объем оперативной памяти узла может достигать нескольких терабайт.
Рассмотрим варианты.
Встраиваемые хранилища
Решения, предназначенные для встраивания в программу. Рассчитаны на один узел, не предоставляют средств распределённой обработки.
На каждом узле анализа – своё, отдельное хранилище данных. Проблема доступа к нелокальным данным. Проблема отказоустойчивости.
Примеры:
- SQLite
- RocksDB
- LMDB
- Perset
Системы кэширования
Предназначены для ускорения доступа к данным за счёт хранения в оперативной памяти.
Ставятся между потребителями данных и системой хранения (обычно долговременным хранилищем).
Долговременное или отказоустойчивое хранилище в любом случае необходимо на случай отказов по питанию.
Рассмотрим стратегии кэширования
Сквозное чтение

Опережающее обновление

Обходная запись
Постоянное хранилище обновляется помимо кэша. На предыдущих схемах показано точечным пунктиром.
Сквозная запись

Отложенная запись

Примеры:
- Memcached – популярная система кэширования, но для записи в хранилище требуется обходная запись
- EHCache – система кэширования, поддерживающая различные стратегии
- Hazelcast – решение не только и не столько для кэширования, но в части кэширования поддерживает сквозное чтение и сквозную запись
- Redis – поддерживает постоянное хранение с помощью собственного формата, однако любую из перечисленных выше стратегий по сути необходимо реализовывать вручную
Базы данных и сетки данных в памяти
Базы данных в памяти (IMDB) и сетки данных в памяти (IMDG) – более мощное решение.
Для энергонезависимого хранения непосредственно используется диск, однако данные в основном хранятся в памяти, а диск используется только для журналирования и периодического сохранения “снимков” данных, т.е. для устойчивости к сбоям.
Примеры:
- MemSQL
- VoldDB
- Aerospike
- Apache Geode
- Couchbase
- Apache Ignite
- Hazelcast
- Infinispan
Доступ к данным
Как осуществляется доступ к данным, т.е. как данные доставляются потребителю?

Паттерны взаимодействия
Распространённые паттерны:
- Синхронизация
- RMI/RPC
- Простой обмен сообщениями
- Издатель-подписчик
Синхронизация
Подразумевает синхронизацию между хранилищем и клиентом.
Общая идея:
- при первом подключении клиент запрашивает текущий набор данных
- при последующих подключениях выгружаются только изменения
- новые изменения проталкиваются подключённым клиентам
- Достоинства
- Простой протокол
- У клиента полный набор данных
- Простой в реализации API
- Недостатки
- Время передачи
- Объем данных
- Сложность согласования данных при синхронизации
RMI/RPC
При поступлении новых данных, сервер API вызывает процедуру на подключённом клиенте.
API следит за изменениями в хранилище и уведомляет о них клиента.
Две разновидности паттерна:
- данные передаются как аргумент
- только уведомление, клиент сам запрашивает данные
- Достоинства
- Простой протокол
- Простой в реализации API
- Легко реализовать асинхронную обработку на клиенте
- Недостатки
- Затруднена обработка ошибок
- При высокой частоте обновлений, клиент может не успевать обработать удалённые вызовы
Простой обмен сообщениями
Простая схема запрос-ответ.
Необходимо добавить метки, чтобы избежать передачи одних и тех же данных.
Например, ответ сервера может содержать метку последнего обновления данных (версия или метка времени), а клиент в запросе – отправлять метку последнего запроса данных (аналогично).
- Достоинства
- Простой протокол
- Простой в использовании API
- API не требуется хранить состояние
- Отправляются только новые данные
- Недостатки
- Нет механизма уведомления клиента
- Следствие – бесполезные запросы от клиента
- Возможно большой объём данных
Издатель-подписчик (pub/sub)
Клиент подписывается на некоторую тему, API рассылает всем подписчикам сообщения об изменении/поступлении новых данных.
Есть преимущества перед другими рассмотренными, набирает популярность.
- Достоинства
- Легко реализовать асинхронную обработку на клиенте
- Клиенту не нужно хранить метаданные, описывающие текущее состояние
- API может оптимизировать отправку одинаковых данных нескольким клиентам
- Недостатки
- Более сложный протокол
- Более сложный в реализации API
- API должен хранить метаданные обо всех клиентах и иметь возможность распределять их между серверами в случае сбоя.
Технологии отправки данных клиентам
Рассмотрим распространённые протоколы взаимодействия с клиентами. Для каждого будем обращать внимание на следующие факторы:
- частота сообщений
- направление взаимодействия
- задержка сообщений
- эффективность
- отказоустойчивость
Веб-хуки
Веб-хуки концептуально аналог callback в языках программирования.
Выполняются с помощью HTTP POST-запросов. Клиенты часто реализуются сторонними разработчиками.
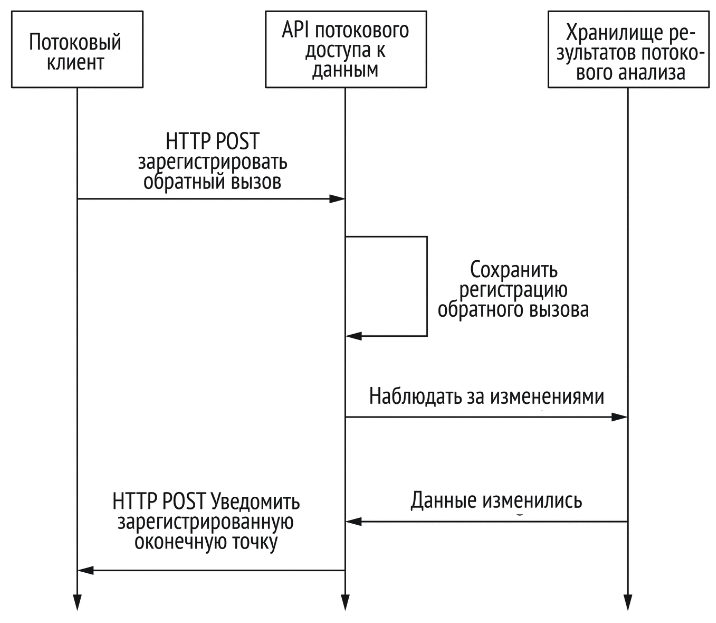
- частота сообщений – невысокая
- направление взаимодействия – одностороннее, сервер к клиенту
- задержка сообщений – средняя
- эффективность – высокая
- отказоустойчивость – никаких гарантий
Для потоковой системы подходит не слишком хорошо.
HTTP long-poll
Клиент устанавливает соединение с сервером, соединение остаётся открытым на неопределённо долгий период времени. Сервер посылает клиенту данные по мере поступления. Соединение закрывается после получения пакета данных и открывается заново.
Клиент управляет опросом наличия изменений, открывая соединение, но за это приходится расплачиваться необходимостью держать соединение со всеми клиентами.
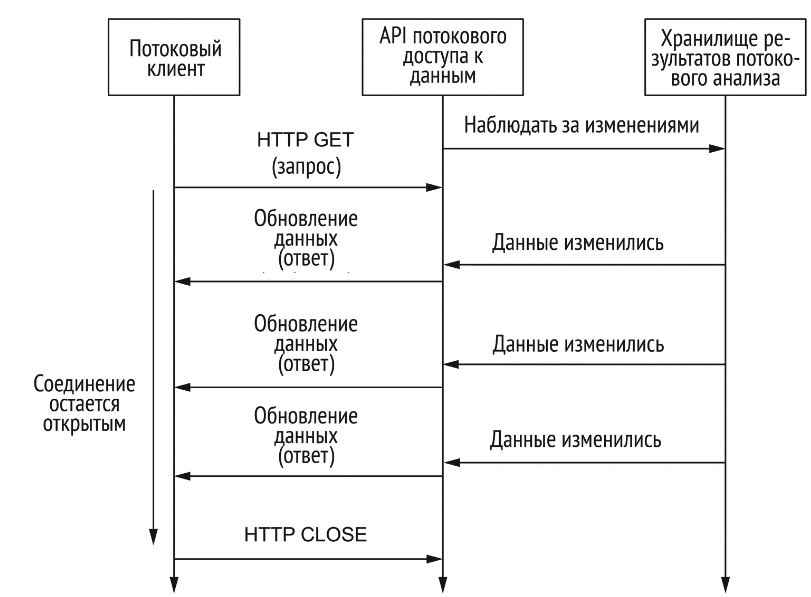
- частота сообщений – низкая
- направление взаимодействия – частично двустороннее
- задержка сообщений – средняя
- эффективность – низкая
- отказоустойчивость – никаких гарантий
Немного ближе к тому, что мы ожидаем увидеть от потокового API, поскольку есть возможность контролировать поток данных со стороны клиента. Но низкая эффективность.
События, посылаемые сервером
Разработан в 2015 году как усовершенствование HTTP long-poll. Устраняет неэффективность открытия и закрытия соединений. Поддерживается прокси-сервер push-уведомлений.
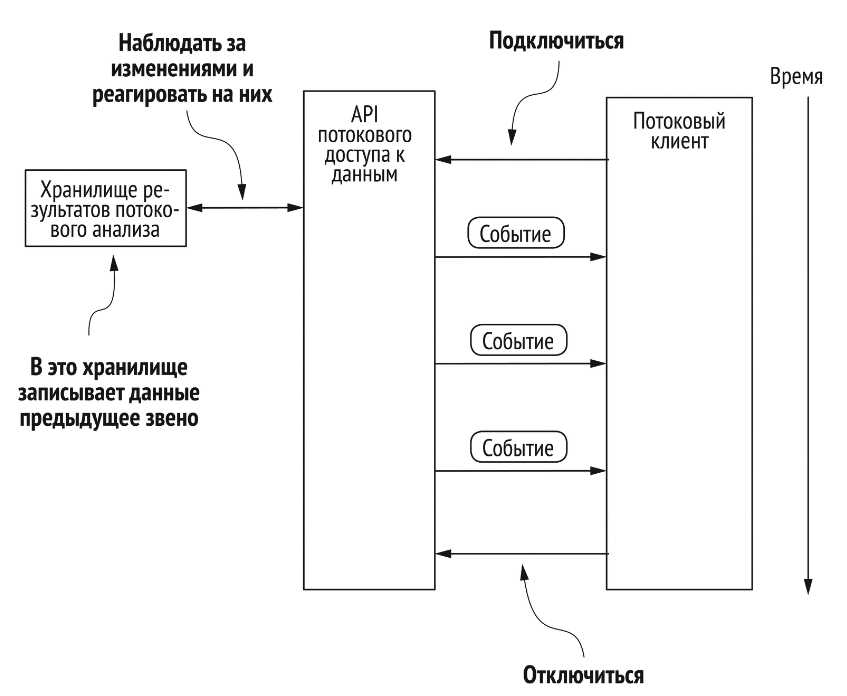
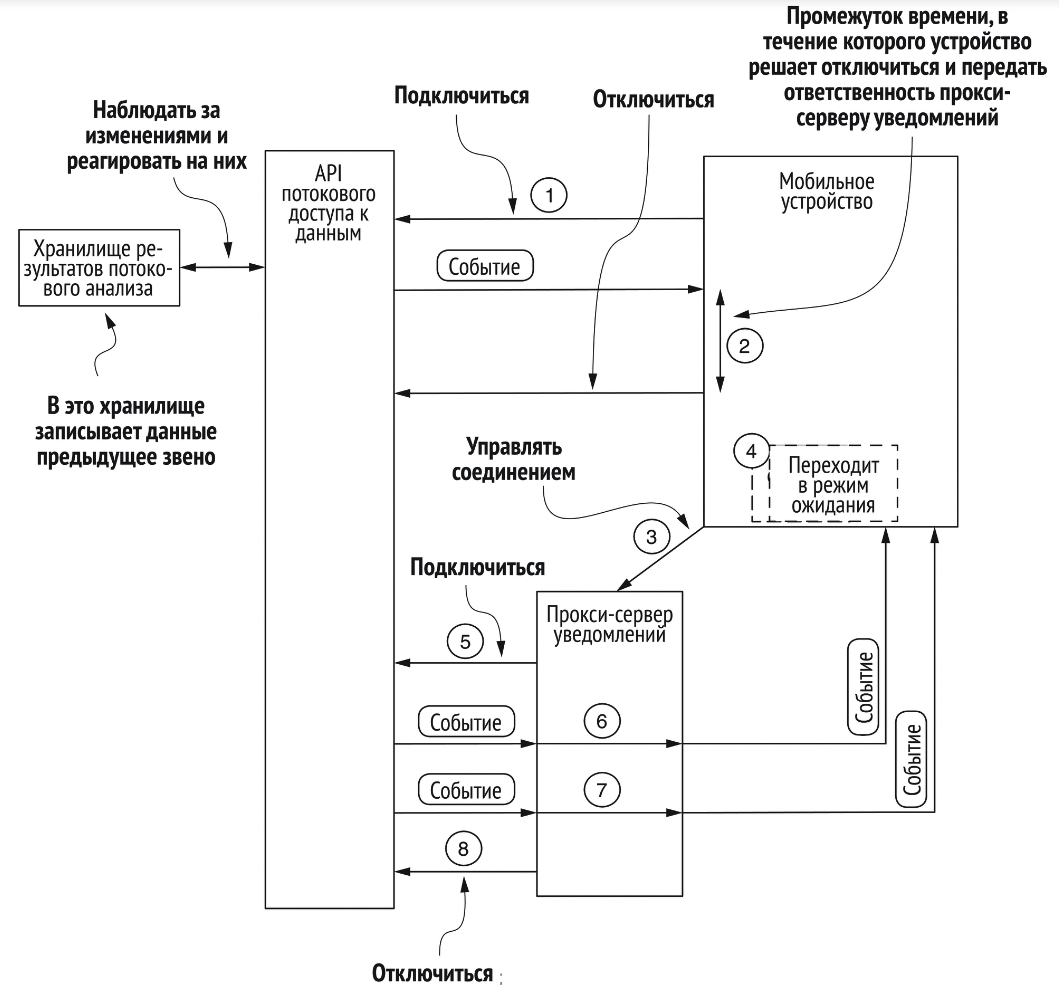
- частота сообщений – высокая
- направление взаимодействия – практически одностороннее, от сервера к клиенту
- задержка сообщений – умеренная
- эффективность – высокая
- отказоустойчивость – никаких гарантий
Веб-сокеты
C 2011 года. Полнодуплексный протокол, транспортный механизм – TCP. Поддерживают все современные браузеры для настольных и мобильных устройств. Обычно он используется в вебе, но для большинства популярных языков программирования имеются библиотеки поддержки.
Интересен в том смысле, что для начального согласования используется HTTP, а затем отправляется запрос переключения протокола и происходит переход на TCP.
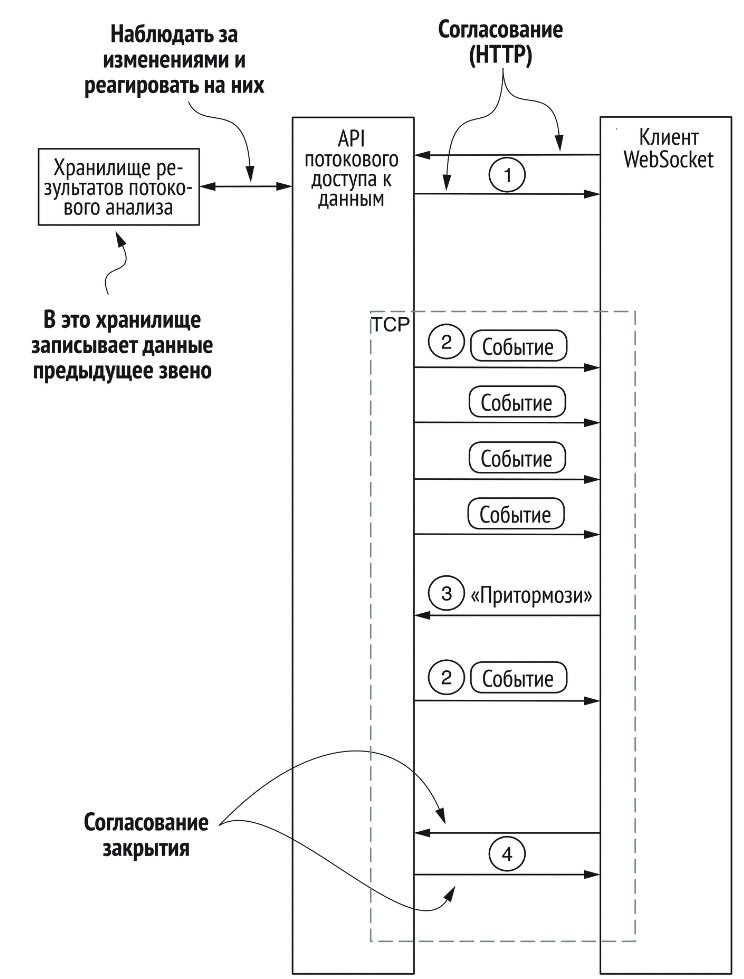
- частота сообщений – высокая
- направление взаимодействия – двустороннее
- задержка сообщений – низкая
- эффективность – высокая
- отказоустойчивость – не даёт гарантий, но двунаправленность позволяет реализовать произовльную семантику поверх.
Быстро становится одним из самых распространённых протоколов в системах потоковой обработки, в первую очередь в силу эффективности и гибкости.
В случае клиентов с ограниченными ресурсами, не поддерживающих HTTP, возможно использовать протоколы Data Distribution Service (DDS) и MQ Telemetry Transport (MQTT). Оба протокола используют паттерн издатель-подписчик.
Если же возможностей DDS или MQTT недостаточно, то всегда есть вариант напрямую работать с TCP. Обратная сторона конечно в том, что придётся с нуля разрабатывать весь протокол.